Seeing the recent blog by Van Alst reminded me how low tech process versioning is. As he points out, it requires careful implementation of the processes, to avoid having long running process instances that may cause difficulties when trying to upgrade either the business process, or the infrastructure on which that process is running.
His suggested approach is to implement those BPEL processes, that would normally be long running, as event/message driven processes that can optionally utilise short running BPEL processes. However the disadvantage is the complexity that may be introduced to accommodate the potentially large number of business process versions that need to be supported. Each new version of the business process needs to accommodate existing running process instances that may be at various stages in the event driven implementation. However suitable tooling could be provided to help manage this.
The typical process versioning techniques currently used are:
1) Active processes should continue to use the same process definition (e.g. BPEL) version, while new process instances would use the most recent version.
2) Terminate all currently active processes – this seems a bit extreme, and can only really work if all systems involved have a way to undo or back out the work already done, and then replay the transaction on the new business process.
3) Migrating the process – although some simple changes can be handled using this approach, it can be very difficult to achieve without introducing errors. This is because the control structure of a process may change, or new variables may be added that cannot be initialised 'after the fact'.
So options (2) and (3) may be suitable in rare cases, but they are not a general solution.
The problem with option (1) is that a business process may be changed while a business process instance (or transaction) has not 'touched' all of the BPEL process definitions involved. For simplicity, if we assume a business process is comprised of two BPEL process definitions, A and B – if a business process instance X starts with process A, and waits for some duration (i.e. may be awaiting user input), and in the meantime the business process is updated in such a way that the interface between process definitions A and B are changed. When process instance X restarts in process definition A, and attempts to interact with process definition B, it would fail. This is because process definition B has not previously been involved in business transaction X, and therefore the BPEL engine managing process definition B would not be aware that it needs to actually direct the interaction to an older version of process definition B.
Could process governance provide another solution to this problem?
Understanding what behaviour a service provides, and what behaviour a service requires from other services, may provide the basis for ensuring the appropriate versions of each service work together correctly to deliver a particular version of the overall business process. This means that when one service wants to interact with another service, it should invoke the process definition version that meets its behavioural requirements, and not necessarily the one that is the most recent version.
The other way in which behaviour could be of use is to help determine whether a new version of a particular process definition (i.e. BPEL) is backward compatible with an active process instance associated with an older version of the process definition. If this is the case, then it may be easy to migrate the process instance to a newer process definition, and thus enable the business process instance as a whole to evolve – however this would be subject to the backward compatibility constraint.
So in summary:
First approach is to make each component of the process as simple and short lived as possible, to avoid having to worry about issues related to versioning those components. The system runs using the most up-to-date version of each component, and the complexity in dealing with changes in a business process are managed by the glue between the tasks – the rules that govern how the results of one task are used to trigger one or more other tasks.
The second approach doesn't place restrictions on the long running nature of the individual services, but instead provides a way in which multiple versions of a business process can run simultaneously, and evolve within certain constraints to newer versions of the service components.
The main point is that a business process and the resulting service designs should not be defined with versioning in mind. As far as possible, this needs to be handled as part of a SOI. In the case of the second approach, this can be handled as part of the governance capabilities, by controlling the specific versions of services that are used based on the required behaviour.

Friday, June 12, 2009
Tuesday, May 19, 2009
Choreography comes of age
A choreography, as defined in the WS-CDL spec, "describes peer-to-peer collaborations of parties by defining, from a global viewpoint, their common and complementary observable behavior; where ordered message exchanges result in accomplishing a common business goal."
WS-CDL was ground breaking as a standard for two reasons:
1) Normally a standardisation process occurs when a number of proprietary de-facto standards, supported by different groups within industry, need to be merged to provide a single true standard that all parties are happy with.
No such proprietary standard existed for choreography, and therefore the working group were in the rare position of having to create something from scratch.
2) For introducing the concept of a 'global' model - a global model being a description of the interactions between parties from a neutral or global (i.e. service independent) perspective.
Much respect to Nickolas Kavantzas of ORACLE for dreaming up the idea, as this has spawned a lot of new research, and therefore if WS-CDL has achieved nothing else, it has made a significant contribution to computer science. Pity ORACLE didn't follow up on Nick's excellent contribution by providing an implementation of the standard, especially as they were also the co-chair of the working group.
However WS-CDL has its downsides.
In an attempt to provide a language with a strong formal type system, it has become complex to use. It is perceived by many to be web service specific, due to its affiliation with W3C. However the most damaging aspect is the long running misconception that it is competitive to BPEL.
As mentioned above, WS-CDL is an example of a 'global' model, and therefore provides a service independent view of interactions between participants.
Abstract BPEL is an example of a 'local' model, i.e. it is a service specific view of interactions between that service and its directly associated participants. Therefore the standards are actually complementary, they should be able to work together harmoniously in their separate roles.
The problem is that one of the main disadvantages with WS-CDL is that it does not define its own 'local' model representation that would be fully compatible with the 'global' model language. Although Abstract BPEL can be used to fulfill this role, it is not ideal for the job.
Now choreography has come of age. We have a new champion emerging on the scene in the form of BPMN2.
The popular graphical notation has taken a number of significant steps forward with version 2, including the introduction of a choreography 'global' model to accompany the existing process 'local' model notation.
The benefit of this approach is that it is (1) not perceived to be web service specific, (2) there is a compatible notation between the 'global' and 'local' model perspectives, and (3) it is being incorporated into a standard that is already very popular, and therefore should make it easier for users to adopt the choreography concept.
WS-CDL was ground breaking as a standard for two reasons:
1) Normally a standardisation process occurs when a number of proprietary de-facto standards, supported by different groups within industry, need to be merged to provide a single true standard that all parties are happy with.
No such proprietary standard existed for choreography, and therefore the working group were in the rare position of having to create something from scratch.
2) For introducing the concept of a 'global' model - a global model being a description of the interactions between parties from a neutral or global (i.e. service independent) perspective.
Much respect to Nickolas Kavantzas of ORACLE for dreaming up the idea, as this has spawned a lot of new research, and therefore if WS-CDL has achieved nothing else, it has made a significant contribution to computer science. Pity ORACLE didn't follow up on Nick's excellent contribution by providing an implementation of the standard, especially as they were also the co-chair of the working group.
However WS-CDL has its downsides.
In an attempt to provide a language with a strong formal type system, it has become complex to use. It is perceived by many to be web service specific, due to its affiliation with W3C. However the most damaging aspect is the long running misconception that it is competitive to BPEL.
As mentioned above, WS-CDL is an example of a 'global' model, and therefore provides a service independent view of interactions between participants.
Abstract BPEL is an example of a 'local' model, i.e. it is a service specific view of interactions between that service and its directly associated participants. Therefore the standards are actually complementary, they should be able to work together harmoniously in their separate roles.
The problem is that one of the main disadvantages with WS-CDL is that it does not define its own 'local' model representation that would be fully compatible with the 'global' model language. Although Abstract BPEL can be used to fulfill this role, it is not ideal for the job.
Now choreography has come of age. We have a new champion emerging on the scene in the form of BPMN2.
The popular graphical notation has taken a number of significant steps forward with version 2, including the introduction of a choreography 'global' model to accompany the existing process 'local' model notation.
The benefit of this approach is that it is (1) not perceived to be web service specific, (2) there is a compatible notation between the 'global' and 'local' model perspectives, and (3) it is being incorporated into a standard that is already very popular, and therefore should make it easier for users to adopt the choreography concept.
Monday, May 18, 2009
BPM console blog moved
I moved the BPM console blog to a new location:
http://relative-order.blogspot.com/
http://relative-order.blogspot.com/
Sunday, February 15, 2009
Testable architectures
Steve has posted an interesting article on his recent use of the testable architectures approach he's been discussing for several years. It's obviously closely related to what we're trying to achieve together on Process Governance, so take a look.
Thursday, January 15, 2009
Developing BPM console plugins
I committed a first draft of a plugin mechanism that allows composition of BPM console features more easily. Initially we'd been looking for a convenient way to deal with the differences in jbpm3 and jbpm4, but now it has proven to be good solution for console mash-ups in general. For instance future integration or composition with Guvnor.
The idea is simple: While providing common elements like authentication, configuration and look and feel, the console needs to be assembled out of common and proprietary features. Not everything we build into it, works across BPM runtimes even though it's our foremost goal.
Fortunately GWT already ships with an extension mechanism called "Deferred Binding". It allows you to replace or generate components at build time. Build time in our case means maven, and the easiest way to customize a maven build is by providing different sets of dependencies. Unlike the regular GWT compilation which is restricted to a subset of the JDK, the deferred binding has access to the full API, including classloading. It actually happens before the GWT compiler kicks in.
Great. That means our plugin loader can build upon the availability of plugins in the classloading scope.
Maven already provides the dependency management, then we are set.
Let's look at an example. Trunk contains a plugin-example that should get you going. Take a look at the pom.xml dependencies first. Any plugin has a dependency on the console plugin API:
It ships with a few concepts that we need to clarify before we can move on. The console acts as a Workspace. A Workspace contains Editors, which are composed of different Views. Developing a plugin actually means implementing an Editor and providing a workspace configuration (workspace.cfg).
When building the console, the deferred binding generates and links the code that is required to associate all Editors in a workspace configuration with the console framework. Sounds terrible, but a plugin developer only needs to know a few interfaces and create a workspace configuration.
An Editor is your plugin root implementation. It needs to be uniquely identified (editorId) and contribute to the main menu (MenuSection). It can contain one or more views:
The editor and it's views share an ApplicationContext that gives you access to common things like authentication, configuration, logging, etc.
Besides that, you can leverage anything GWT provides for implementing your plugin.
I think you get the idea. Take a look at the plugin example (Google Maps integration), especially the editor implementation.
In order to enable this workspace configuration you need to build with "mvn -Pplugin-example" switch.
Discussion
Please join us in the overlord forum for further discussions.
The idea is simple: While providing common elements like authentication, configuration and look and feel, the console needs to be assembled out of common and proprietary features. Not everything we build into it, works across BPM runtimes even though it's our foremost goal.
Fortunately GWT already ships with an extension mechanism called "Deferred Binding". It allows you to replace or generate components at build time. Build time in our case means maven, and the easiest way to customize a maven build is by providing different sets of dependencies. Unlike the regular GWT compilation which is restricted to a subset of the JDK, the deferred binding has access to the full API, including classloading. It actually happens before the GWT compiler kicks in.
Great. That means our plugin loader can build upon the availability of plugins in the classloading scope.
Maven already provides the dependency management, then we are set.
Let's look at an example. Trunk contains a plugin-example that should get you going. Take a look at the pom.xml dependencies first. Any plugin has a dependency on the console plugin API:
<dependency>
<groupId>org.jbpm.jbpm3</groupId>
<artifactId>gwt-console-plugin</artifactId>
<version>1.0.0-SNAPSHOT</version>
</dependency>
It ships with a few concepts that we need to clarify before we can move on. The console acts as a Workspace. A Workspace contains Editors, which are composed of different Views. Developing a plugin actually means implementing an Editor and providing a workspace configuration (workspace.cfg).
When building the console, the deferred binding generates and links the code that is required to associate all Editors in a workspace configuration with the console framework. Sounds terrible, but a plugin developer only needs to know a few interfaces and create a workspace configuration.
public abstract class Editor extends Panel
{
protected ApplicationContext appContext;
public abstract String getEditorId();
public abstract String getTitle();
public abstract String getIconCSS();
public abstract MenuSection provideMenuSection();
[...]
}
An Editor is your plugin root implementation. It needs to be uniquely identified (editorId) and contribute to the main menu (MenuSection). It can contain one or more views:
public abstract class View extends Panel
{
protected ApplicationContext appContext;
public abstract String getViewId();
public abstract String getIconCSS();
}
The editor and it's views share an ApplicationContext that gives you access to common things like authentication, configuration, logging, etc.
public interface ApplicationContext
{
[...]
void displayMessage(String message, boolean isError);
Authentication getAuthentication();
}
Besides that, you can leverage anything GWT provides for implementing your plugin.
I think you get the idea. Take a look at the plugin example (Google Maps integration), especially the editor implementation.
In order to enable this workspace configuration you need to build with "mvn -Pplugin-example" switch.
Discussion
Please join us in the overlord forum for further discussions.
Tuesday, January 13, 2009
Typing a BPM system
While working on the GWT console I came across two requirements that I couldn’t realize easily within the console: process variables inspection and task management forms. Both solutions should allow modification of data associated with a process through web based forms.
In order to build such a form and to process the data submitted through it you’d need some kind of data type description associated with the process definition. Even if you don’t intend to build those forms at runtime, but instead chose a design time approach you would still be left with the question of validation.
But not only that. The tooling that helps you build the task forms at design time would need some data type description as well. How would know what types to chose for UI elements and the keys to access it?
This leads to an additional requirement: Once you got the data type description and you successfully modeled your form, how do access the data at runtime? Somehow the process data needs to extracted and displayed through the forms.
One thing you may realize at this point is that a simple example like the task management forms already require type information across BPM components. It start’s with the tooling, is used to extract data at runtime and finally describes how the forms should be rendered.
One thing that jumps to my mind XML and XSD. Ok, I admit that I have been working on the JBoss web service stack, but other problem domains chose such a solution as well. Just think of heterogenous (i.e. ESB) or event based systems (i.e. CEP). And they do so for good reasons:
If you add XForms to the picture we are one step closer to solving my initial task management problem: Describe your data types through XSD, extract it by using XPath and display it through XForms.
But there’s more to it: Decoupled producer and consumers in SOA, in which BPM plays in important role, would greatly benefit from such a type system as well. Any invocation between a process and a service could then be constrained to the type information at hand.
In order to build such a form and to process the data submitted through it you’d need some kind of data type description associated with the process definition. Even if you don’t intend to build those forms at runtime, but instead chose a design time approach you would still be left with the question of validation.
But not only that. The tooling that helps you build the task forms at design time would need some data type description as well. How would know what types to chose for UI elements and the keys to access it?
This leads to an additional requirement: Once you got the data type description and you successfully modeled your form, how do access the data at runtime? Somehow the process data needs to extracted and displayed through the forms.
One thing you may realize at this point is that a simple example like the task management forms already require type information across BPM components. It start’s with the tooling, is used to extract data at runtime and finally describes how the forms should be rendered.
One thing that jumps to my mind XML and XSD. Ok, I admit that I have been working on the JBoss web service stack, but other problem domains chose such a solution as well. Just think of heterogenous (i.e. ESB) or event based systems (i.e. CEP). And they do so for good reasons:
- You get a data type model that supports structured and simple types
- It can be validated through XSD
- Access to the data can either be done programatically or through XPath
- Data can be represented in Java or XML
If you add XForms to the picture we are one step closer to solving my initial task management problem: Describe your data types through XSD, extract it by using XPath and display it through XForms.
But there’s more to it: Decoupled producer and consumers in SOA, in which BPM plays in important role, would greatly benefit from such a type system as well. Any invocation between a process and a service could then be constrained to the type information at hand.
Monday, January 12, 2009
GWT console Beta2
Some things changed in Beta2 others did improve and I’d like to give you a quick update on what happened the last two month.
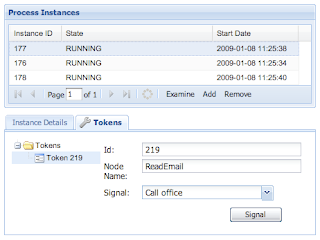
TokenEditor
Something you may already know from the JSF console and what is commonly used during development is the possibility to signal tokens directly from the console. We’ve added that feature to the GWT console under the section “Development tools”. You’ll notice those by the little wrench icon in the upper corner. These tools will be available to a particular role only, once we add authorization to the editors.
Report server integration
Beta2 drops the gchart, the client side Javascript charting library and instead switched to BIRT. There have been several reasons leading to this decision.
On the one hand we’ve realized that biggest challenge with reporting is not rendering itself (which gchart could have provided) but the tooling that needs to go along with it.
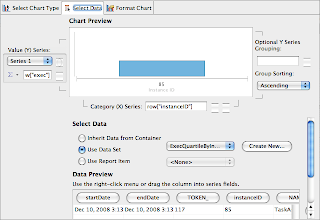
We’ve realized that it’s close to impossible to come up with the one and only BPM report that pleases everyone. Most reporting and dashboard applications are actually quiet the opposite: Highly customized towards particular users and their problem domain. This is the approach we are taking with BIRT as well. The jBPM console ships with stock reports, that can be extended or even be replaced.
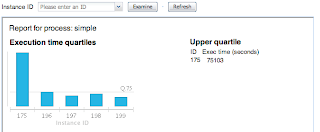
If you are interested in jBPM reporting a good starting point would be the report server project introduction.
Task management
We’ve also added the first task management functionality which currently does focus on task assignments.
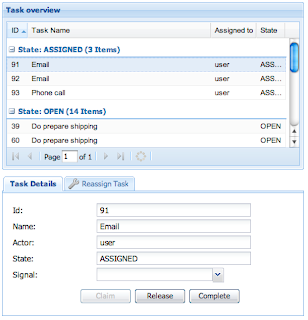
The current release allows you to claim tasks, complete them by signaling or reassign tasks to a particular user or group. Future console version will embed task forms for human interaction, but this area in particular requires further discussion.
Stay tuned...
TokenEditor
Something you may already know from the JSF console and what is commonly used during development is the possibility to signal tokens directly from the console. We’ve added that feature to the GWT console under the section “Development tools”. You’ll notice those by the little wrench icon in the upper corner. These tools will be available to a particular role only, once we add authorization to the editors.

Report server integration
Beta2 drops the gchart, the client side Javascript charting library and instead switched to BIRT. There have been several reasons leading to this decision.
On the one hand we’ve realized that biggest challenge with reporting is not rendering itself (which gchart could have provided) but the tooling that needs to go along with it.

We’ve realized that it’s close to impossible to come up with the one and only BPM report that pleases everyone. Most reporting and dashboard applications are actually quiet the opposite: Highly customized towards particular users and their problem domain. This is the approach we are taking with BIRT as well. The jBPM console ships with stock reports, that can be extended or even be replaced.
If you are interested in jBPM reporting a good starting point would be the report server project introduction.

Task management
We’ve also added the first task management functionality which currently does focus on task assignments.

The current release allows you to claim tasks, complete them by signaling or reassign tasks to a particular user or group. Future console version will embed task forms for human interaction, but this area in particular requires further discussion.
Stay tuned...
Subscribe to:
Posts (Atom)